Reference: "SWE-BENCH: CAN LANGUAGE MODELS RESOLVE REAL-WORLD GITHUB ISSUES?" [arxiv]
1. 서론
2023년 인공지능 기술은 소프트웨어 개발 영역에서 급속도로 발전하고 있었다. GitHub Copilot과 ChatGPT 등 다양한 AI 코딩 어시스턴트들이 상용화되며 개발자들의 일상에 깊숙이 자리 잡기 시작했다. 그러나 이러한 발전에도 불구하고 우리는 근본적인 질문 하나에 직면하게 된다.
이 AI 시스템들이 정말로 실제 소프트웨어 엔지니어링 업무를 수행할 수 있을까? 기존의 코드 생성 벤치마크들은 이미 포화 상태에 이르렀다. 최신 언어 모델들은 HumanEval과 같은 표준 평가에서 90% 이상의 높은 점수를 기록하고 있었다. 하지만 실제 개발 현장에서는 여전히 명확한 한계가 존재했다. 이러한 격차는 기존 벤치마크가 실제 소프트웨어 엔지니어링의 복잡성을 제대로 반영하지 못하고 있음을 시사한다.
Princeton 대학의 연구팀은 이 문제를 해결하기 위해 SWE-bench를 제안했다. 이는 실제 GitHub의 이슈와 Pull Request를 기반으로 구축된 벤치마크로 언어 모델의 진정한 소프트웨어 엔지니어링 능력을 평가하고자 한다. 연구 결과는 충격적이었다. 2023년 당시 최고 성능을 자랑하던 Claude 2 모델조차 전체 문제의 겨우 1.96%만 해결할 수 있었던 것이다. 이는 현재의 AI 기술과 실제 소프트웨어 엔지니어링 사이에 여전히 큰 간극이 존재함을 명확히 보여준다.
2. HumanEval의 한계와 문제점
코드 생성 능력을 평가하기 위한 벤치마크로 가장 널리 사용되어 온 것은 HumanEval이다. 2021년 OpenAI의 Codex 논문과 함께 소개된 이 벤치마크는 164개의 Python 프로그래밍 문제로 구성되어 있으며 각 문제는 함수 시그니처와 독스트링 그리고 몇 개의 테스트 케이스를 제공한다. 모델은 주어진 함수를 완성하는 코드를 생성해야 하며 생성된 코드가 테스트를 통과하는지 여부로 평가받는다.
그러나 HumanEval은 실제 소프트웨어 개발 환경을 반영하기에는 여러 근본적인 한계를 지니고 있다.
첫째 문제의 규모가 지나치게 작다. HumanEval의 문제들은 평균 9줄 정도의 코드로 해결 가능하며 대부분 단일 함수만 작성하면 된다. 이는 알고리즘 퀴즈에 가까우며 실제 개발에서 마주치는 복잡한 문제와는 거리가 멀다. 실제 소프트웨어 엔지니어링에서는 수백 줄의 코드를 수정하고 여러 파일에 걸친 변경을 조율하며 복잡한 의존성을 관리해야 하는 경우가 대부분이다.
둘째 HumanEval의 문제들은 컨텍스트가 전혀 없는 독립적인 함수들이다. 실제 개발 환경에서는 대규모 코드베이스 내에서 작업해야 하며 다른 모듈들과의 상호작용을 이해하고 기존 코드의 스타일과 구조를 따라야 한다. 또한 파일 간 의존성을 파악하고 변경사항이 다른 부분에 미치는 영향을 고려해야 한다. HumanEval은 이러한 현실적인 측면을 전혀 반영하지 못한다.
마지막으로 가장 중요한 문제는 현실성의 부족이다. 실제 소프트웨어 엔지니어링은 대규모 코드베이스 탐색과 여러 파일 간 상호작용 이해와 기존 코드의 수정(새로 작성이 아닌)과 복잡한 버그 디버깅과 테스트 작성 및 실행 등 다양한 측면을 포함한다. HumanEval은 이 중 어느 것도 제대로 평가하지 못한다. MBPP와 APPS와 CodeContests 등 다른 유사한 벤치마크들도 이와 비슷한 한계를 공유하고 있다. 이들은 모두 작고 독립적인 문제들로 구성되어 있어 실제 개발 환경의 복잡성을 담아내지 못한다.
3. SWE-bench란
SWE-bench는 이러한 기존 벤치마크의 한계를 극복하기 위해 설계된 새로운 평가 프레임워크다. 핵심 아이디어는 간단하면서도 강력하다. 실제 GitHub에서 발생한 이슈를 해결하는 능력을 측정하자는 것이다. 이를 위해 연구팀은 실제 오픈소스 프로젝트에서 발생한 버그 리포트와 기능 요청 그리고 이를 해결한 Pull Request를 수집했다.
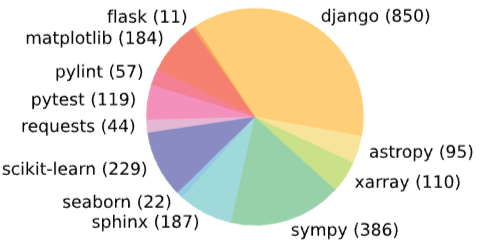
데이터는 12개의 인기 있는 Python 오픈소스 프로젝트로부터 수집되었다. 여기에는 astropy, django, flask, matplotlib, pylint, pytest, requests, scikit-learn, seaborn, sphinx, sympy, xarray가 포함된다. 이 중 django가 850개로 가장 많은 문제를 제공했으며 전체적으로 총 2,294개의 실제 소프트웨어 엔지니어링 문제가 구축되었다.
SWE-bench의 태스크 구조는 명확하다. 모델은 입력으로 문제 설명과 코드베이스를 받는다. 문제 설명은 실제 GitHub 이슈의 텍스트이며 코드베이스는 해당 프로젝트의 전체 저장소다. 모델은 이를 바탕으로 패치 파일을 생성해야 한다. 패치 파일은 유닉스 diff 형식으로 어떤 파일의 어떤 줄을 어떻게 수정할지를 명시한다. 평가는 생성된 패치를 실제로 적용한 후, 저장소에 포함된 단위 테스트를 실행하여 이루어진다.
SWE-bench가 혁신적인 이유는 여러 가지다. 우선 현실적인 복잡도를 반영한다. 평균적으로 각 문제는 195단어의 설명을 가지고 있으며 코드베이스는 3,010개의 파일과 438,000줄로 구성되어 있다. 해결책은 평균적으로 1.7개의 파일을 수정하고 32.8줄을 변경한다. 테스트는 평균 120개가 실행되는데 이 중 9.1개가 실패에서 성공으로 바뀌어야 하며(fail-to-pass), 나머지 111.8개는 계속 성공을 유지해야 한다(pass-to-pass).

또한 실행 기반 평가를 사용한다는 점도 중요하다. 단순히 코드를 생성하는 것으로 끝나지 않고 실제로 패치를 적용하고 테스트를 실행하여 문제가 해결되었는지 확인한다. 이는 생성된 코드가 실제로 작동하는지, 기존 기능을 망가뜨리지 않는지를 엄격하게 검증한다. 뿐만 아니라 SWE-bench는 지속적으로 업데이트 가능하도록 설계되었다. 데이터 수집 과정이 자동화되어 있어 새로운 Pull Request가 merge될 때마다 새로운 문제를 추가할 수 있다. 이는 모델이 훈련 데이터에서 본 적 없는 최신 문제로 평가받을 수 있음을 의미하며 데이터 오염 문제를 방지한다.
5. 검색 방법: BM25, Oracle, Dense
SWE-bench의 가장 큰 도전 과제 중 하나는 코드베이스의 크기다. 평균적으로 각 문제의 코드베이스는 438,000줄의 코드를 포함한다. 이는 대부분의 언어 모델의 컨텍스트 윈도우를 훨씬 초과하는 양이다. 따라서 전체 코드베이스를 모델에게 제공하는 것은 불가능하며 관련 있는 파일들만을 선별적으로 제공해야 한다. 연구팀은 이를 위해 여러 검색 방법을 실험했다.
BM25 검색 방법은 가장 기본적인 접근법이다. BM25는 정보 검색 분야에서 널리 사용되는 희소 검색 알고리즘으로, 코드 파일을 문서로, 이슈 설명을 쿼리로 간주하여 관련성 점수를 계산한다. 연구팀은 세 가지 다른 컨텍스트 길이 제한을 실험했다. 13,000 토큰, 27,000 토큰, 50,000 토큰이다. 각 제한 내에서 가능한 한 많은 파일을 검색하여 제공했다. 흥미롭게도 모델들은 대부분 가장 짧은 컨텍스트에서 가장 좋은 성능을 보였다. Claude 2의 경우 13,000 토큰에서 1.96%, 27,000 토큰에서 1.87%, 50,000 토큰에서 1.22%의 해결률을 기록했다. 이는 더 많은 컨텍스트가 반드시 좋은 것은 아니며 오히려 노이즈로 작용할 수 있음을 시사한다.

Dense 검색 방법도 고려되었지만, 매우 긴 키와 쿼리 길이, 특히 자연어 쿼리를 사용하여 코드 문서를 검색하는 특이한 설정으로 인해 본 논문의 설정에 적합하지 않았다.
Oracle 검색은 분석을 위한 이상적인 시나리오다. 여기서는 실제 Pull Request에서 수정된 파일들을 "검색"하여 제공한다. 즉, 모델이 정확히 어떤 파일을 수정해야 하는지 미리 알려주는 것이다. 이는 현실적이지 않은 설정이지만, 검색의 중요성과 모델의 실제 능력을 분리하여 분석하는 데 유용하다. Oracle 설정에서 Claude 2는 4.80%의 해결률을 보였다. 이는 BM25 13,000 토큰 설정의 1.96%보다 2배 이상 높은 수치다. 그러나 여전히 95% 이상의 문제를 해결하지 못한다는 점에서, 검색만이 문제가 아니라 모델 자체의 한계도 명확히 존재함을 알 수 있다.
검색 성능을 정량적으로 분석하기 위해, 연구팀은 BM25가 Oracle 파일을 얼마나 잘 찾아내는지 측정했다. 13,000 토큰 제한에서 BM25는 평균적으로 Oracle 파일의 29.58%만을 검색했다. 27,000 토큰으로 늘리면 44.41%로 향상되고, 50,000 토큰에서는 51.06%를 기록했다. 더 구체적으로 살펴보면, 13,000 토큰 설정에서 BM25가 모든 Oracle 파일을 찾아낸 경우는 26.09%에 불과했다. 반대로 Oracle 파일을 하나도 찾지 못한 경우는 거의 절반에 달했다. 이는 검색이 여전히 큰 병목 지점임을 명확히 보여준다.
검색 방법의 중요성은 SWE-bench의 핵심 도전 과제 중 하나다. 현재의 BM25 방법은 단순하고 구현이 쉽지만, 성능에 명확한 한계가 있다. 코드 구조를 이해하는 검색 방법, 의존성 그래프를 활용하는 검색, 또는 LM 자체가 능동적으로 파일을 탐색하는 방법 등이 향후 연구 방향으로 제시되고 있다.
6. 컨텍스트 길이와 성능의 상관관계
SWE-bench 연구에서 가장 흥미롭고 중요한 발견 중 하나는 컨텍스트 길이가 모델 성능에 미치는 영향이다. 직관적으로는 더 많은 컨텍스트를 제공할수록 모델이 더 잘 수행할 것이라 예상할 수 있다. 그러나 실험 결과는 정반대였다.
Claude 2를 대상으로 한 분석에서, 연구팀은 전체 입력 토큰 수에 따라 문제들을 네 그룹으로 나누었다. 20,000 토큰 미만, 20,000-50,000 토큰, 50,000-100,000 토큰, 100,000 토큰 이상이다. 놀랍게도 컨텍스트가 길어질수록 성능이 급격히 하락했다. 20,000 토큰 미만의 문제에서는 상대적으로 높은 해결률을 보였지만, 100,000 토큰 이상의 문제에서는 거의 해결하지 못했다. 이는 단순히 문제가 더 어렵기 때문이 아니라, 긴 컨텍스트 자체가 모델의 성능을 저해하는 요인임을 보여준다.

더 흥미로운 것은 이슈 설명의 길이와 성능의 관계다. 이슈 설명만의 토큰 수로 문제들을 나누어 분석했을 때, 컨텍스트 길이만큼 강한 부정적 상관관계는 보이지 않았다. 즉, 문제 설명이 길다고 해서 성능이 크게 떨어지지는 않았다. 이는 성능 저하의 주범이 긴 이슈 설명이 아니라 방대한 코드 컨텍스트임을 의미한다.
왜 긴 코드 컨텍스트가 문제일까? 연구팀은 여러 가설을 제시한다. 첫째, 모델이 관련 있는 코드를 찾아내는 데 어려움을 겪는다. 수천 줄의 코드 중에서 정확히 수정해야 할 몇 줄을 찾는 것은 사람에게도 어려운 작업이다. 모델은 이 "지역화(localization)" 문제에 특히 취약한 것으로 보인다. 둘째, 긴 컨텍스트는 모델의 주의력을 분산시킨다. 최근 연구들에서 밝혀진 바와 같이, 언어 모델은 긴 컨텍스트에서 중요한 정보를 놓치는 경향이 있다. 특히 컨텍스트 중간에 위치한 정보는 시작이나 끝에 위치한 정보보다 덜 주목받는다.
이러한 문제를 더 명확히 확인하기 위해 연구팀은 "Oracle-collapsed" 설정을 실험했다. 이는 Oracle 파일들을 제공하되 실제로 수정되는 줄 주변 15줄만 보여주고 나머지는 접는 방식이다. 즉, 어떤 파일을 수정해야 하는지뿐만 아니라 그 파일의 어떤 부분을 봐야 하는지까지 알려주는 것이다. 이 설정에서 Claude 2의 성능은 4.8%에서 5.93%로 향상되었고, GPT-4는 1.3%에서 3.4%로 크게 개선되었다. 이는 코드 지역화가 정말 큰 병목 지점임을 실증적으로 보여준다.

또한 연구팀은 BM25의 컨텍스트 길이를 늘렸을 때의 효과도 분석했다. 앞서 언급했듯이, 13,000 토큰에서 27,000, 50,000 토큰으로 늘리면 BM25가 찾아내는 Oracle 파일의 비율이 증가한다. 그러나 모델의 실제 성능은 오히려 감소했다. 이는 관련 있는 파일을 더 많이 제공하더라도 동시에 관련 없는 파일도 더 많이 제공되어 노이즈가 증가하기 때문이다. 모델은 추가된 관련 파일로부터 얻는 이득보다 증가된 노이즈로 인한 손실이 더 크다.
이러한 발견들은 SWE-bench 해결을 위한 중요한 통찰을 제공한다. 단순히 모델의 컨텍스트 윈도우를 늘리는 것만으로는 충분하지 않다. 모델이 긴 컨텍스트에서도 관련 정보를 효과적으로 찾아내고 활용할 수 있는 능력이 필요하다. 이는 더 나은 검색 메커니즘, 계층적 코드 이해, 또는 능동적인 코드베이스 탐색 전략 등을 통해 개선될 수 있을 것이다.
8. 2023년도의 결론
2023년 SWE-bench 논문의 결과는 충격적이면서도 명확했다. 당시 최고 성능을 자랑하던 언어 모델들조차 실제 소프트웨어 엔지니어링 작업에서는 매우 제한적인 능력만을 보여주었다. BM25 검색을 사용한 기본 설정에서, Claude 2는 2,294개 문제 중 단 45개, 즉 1.96%만을 해결했다. 이는 HumanEval에서의 성능과는 극명한 대조를 이루는 결과였다.
다른 모델들의 성능은 더욱 낮았다. GPT-4는 1.31%, ChatGPT-3.5는 0.17%에 불과했다. 연구팀이 파인튜닝한 SWE-Llama 7b와 13b도 각각 0.70%로 Claude 2의 절반에도 미치지 못했다. 심지어 Oracle 검색을 사용하여 정확히 수정해야 할 파일을 알려주었을 때도 Claude 2는 4.8%만을 해결했다. 이는 검색이 주요 병목이기는 하지만, 그것이 전부가 아님을 의미한다.
연구팀은 정성적 분석을 통해 모델들이 보이는 구체적인 한계를 파악했다. 첫째, 모델들은 원시적인 Python 코드를 작성하는 경향이 있었다. 기존 코드베이스에 있는 유틸리티 함수나 서드파티 라이브러리를 활용하지 못하고, 처음부터 모든 것을 구현하려 했다. 둘째, "탐욕적인" 접근을 보였다. 문제를 정확히 해결하는 것에만 집중하고 코드 스타일이나 논리적 제약은 무시했다. 예를 들어, 상대 임포트를 사용해야 하는 곳에 절대 임포트를 사용하는 식이다. 셋째, 구조적 개선을 하지 못했다. 사람이 작성한 해결책은 종종 문제를 해결하면서 동시에 코드 구조를 개선하고 미래의 잠재적 문제까지 예방한다. 그러나 모델들은 주어진 문제만 최소한으로 해결하려 했다.
모델이 생성한 패치의 특성도 흥미로웠다. 성공적으로 적용된 패치들의 통계를 보면, 평균 19.6줄을 수정하는데 이는 실제 해결책의 평균 44.1줄의 절반도 안 되는 수준이다. 또한 대부분 하나의 파일만 수정했으며 평균 1.1개의 함수만 변경했다. 이는 모델들이 간단하고 지역적인 수정만 시도하며 여러 파일에 걸친 복잡한 변경은 시도조차 하지 못함을 보여준다.
연구팀은 SWE-bench가 언어 모델 발전의 새로운 프론티어를 제시한다고 결론지었다. 기존 벤치마크들은 포화 상태에 이르렀지만, SWE-bench는 여전히 모델들에게 큰 도전이다. 1.96%라는 낮은 성능은 실망스러울 수 있지만 동시에 엄청난 개선 여지가 있음을 의미한다. 향후 연구 방향으로는 에이전트 기반 접근, 도구 활용 언어 모델, 실행 피드백을 통한 반복적 개선, 더 나은 코드 검색 및 지역화 방법 등이 제시되었다.
SWE-bench는 단순히 새로운 벤치마크를 넘어, 실제 소프트웨어 엔지니어링의 복잡성을 AI 연구에 가져왔다는 점에서 의의가 크다. 이는 AI가 진정으로 유용한 개발 도구가 되기 위해 넘어야 할 산이 무엇인지 명확히 보여주었다.
9. 2025년의 변화와 현재
2023년 SWE-bench 논문 발표 이후 2년이 지난 지금, AI 분야는 놀라운 발전을 이루었다. 공식 웹사이트 www.swebench.com에 따르면, 현재의 최고 성능 모델들은 2023년과는 비교할 수 없을 정도로 향상된 결과를 보여주고 있다.
가장 주목할 만한 변화는 SWE-bench Verified의 등장이다. 2024년 8월, OpenAI와의 협력으로 탄생한 이 변형은 사람이 직접 검증한 500개의 고품질 문제로 구성되어 있다. 원래의 Full 데이터셋은 2,294개의 문제를 포함하지만, 평가 시간과 비용이 많이 들고 일부 문제의 품질이 불균등할 수 있다는 한계가 있었다. Verified는 이러한 문제를 해결하기 위해 큐레이션된 것으로, 현재 널리 사용되고 있다.
2025년 현재, SWE-bench Verified에서의 최고 성능은 70%를 넘어섰다. TRAE는 75.2%를 달성했으며, mini-SWE-agent와 Claude 4.5 Sonnet을 결합한 LM은 70.60%를 기록했다. 이는 2023년 Claude 2의 1.96%와 비교하면 약 35배 향상된 수치다. 단 2년 만에 이루어진 이 급격한 발전은 AI 연구의 놀라운 속도를 보여준다.
Full 데이터셋에서의 성능도 크게 개선되었다. 2025년 2월 기준으로 최고 성능 모델은 약 33%의 해결률을 보이고 있다. 이는 2023년의 1.96%에 비하면 10배 이상 향상된 것이다. 그러나 여전히 약 75%의 문제는 해결하지 못하고 있어, SWE-bench가 계속해서 도전적인 벤치마크임을 증명한다.
이러한 성능 향상을 가능하게 한 요인은 여러 가지다. 첫째, 기반 모델 자체의 발전이다. Claude 3.7 Sonnet, Claude 4, GPT-5, Gemini 2.5 등 새로운 세대의 모델들은 코드 이해와 생성 능력이 크게 향상되었다. 특히 Claude 모델들은 현재 코드 작업에서 최고 수준으로 평가받고 있다.
둘째, 에이전트 기반 접근법의 발전이다. 2025년 7월, mini-SWE-agent는 단 100줄의 Python 코드로 SWE-bench Verified에서 65%를 달성했다. 이는 복잡한 시스템 없이도 효과적인 에이전트를 구축할 수 있음을 보여준다. mini-SWE-agent는 bash 명령어만 사용하며, 복잡한 도구나 프레임워크 없이 LM이 쉘의 모든 기능을 활용하도록 한다.
셋째, 앙상블 기법의 활용이다. 여러 번의 시도를 통해 후보 해결책들을 생성하고, 가장 유망한 것을 선택하는 방식이 효과적임이 입증되었다. Augment Code의 연구에 따르면, 앙상블 기법은 3-8%의 추가 성능 향상을 가져올 수 있다. 다만 비용 증가가 실용성을 제한하는 요인이다.
그러나 급격한 성능 향상에도 도전은 여전히 남아있다. SWE-bench Pro라는 새로운 벤치마크가 2025년에 등장했는데, 이는 41개의 전문 저장소에서 1,865개의 작업을 포함한다. 특히 주목할 점은 276개의 문제가 18개 스타트업의 비공개 독점 코드베이스에서 수집되었다는 것이다. 이 Private Commercial Subset에서 Claude Opus 4.1의 성능은 22.7%에서 17.8%로, GPT-5는 23.1%에서 14.9%로 하락했다. 이는 공개 오픈소스 코드에서 학습한 모델들이 새로운, 이전에 본 적 없는 코드베이스에서는 여전히 어려움을 겪음을 보여준다.
또한 모델들의 결과는 여전히 불안정하다. Augment Code의 연구에 따르면, 같은 문제에 대해 50개 샘플 중 두 개를 무작위로 선택했을 때, 두 시도의 결과가 다른 경우가 대부분이었다. 이는 모델의 추론 과정이 아직 신뢰할 수 없으며 재현 가능한 결과를 보장하기 어렵다는 것을 의미한다.
비용도 여전히 큰 고려사항이다. 고성능을 달성하는 시스템들은 종종 수십 번의 시도와 앙상블을 사용하는데 이는 실용적인 사용에는 비현실적인 비용을 수반한다. 예를 들어, Anthropic의 70.3% 결과는 복잡한 앙상블 기법을 사용했지만, 현재 모델 서빙 비용에서는 실제 사용하기 어렵다.
결론적으로, 2023년부터 2025년까지 SWE-bench에서의 발전은 AI 분야의 급속한 진보를 보여준다. 1.96%에서 71%로의 도약은 분명 놀라운 성과다. 그러나 이 수치를 냉정하게 분석하면 여전히 약 30%의 문제가 해결되지 않고 있다는 사실을 간과할 수 없다.소프트웨어 개발의 특성상, 일반적인 작업과 달리 단 한 줄의 오류도 시스템 전체의 오작동을 초래할 수 있다. 70-80%의 정확도는 많은 분야에서 우수한 성과로 평가받지만 프로덕션 환경에서는 사실상 사용 불가능한 수준이다. 실용적 관점에서 개발자를 대체하기 위해서는 최소 99% 이상, 이상적으로는 99.99%의 정확도가 요구된다.현재의 발전 속도를 고려하더라도, 70%에서 99.99%로 도달하는 것은 1.96%에서 70%로 도약하는 것과는 질적으로 다른 차원의 문제다. 마지막 1%를 개선하는 것이 처음 50%를 달성하는 것보다 훨씬 어려울 것이다. 따라서 AI가 개발자를 완전히 대체할 것이라는 낙관론과 대체가 불가능하다는 비관론 모두 성급한 판단일 수 있다. 기술의 발전 가능성을 인정하면서도 실제 현장 적용에 필요한 신뢰성 수준을 냉철히 고려하는 중립적 시각이 필요한 시점이다.
'AI' 카테고리의 다른 글
| [AI 논문 리뷰] SWE-agent (0) | 2026.01.19 |
|---|---|
| [AI 논문 리뷰] Codex: 자연어로 코드를 생성하는 AI의 등장 (0) | 2026.01.19 |
| LLM: 코드를 이해하고 생성하는 AI 의 등장 (0) | 2026.01.19 |

