Reference: "SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering" [arxiv]
1. 서론
소프트웨어 개발에서 버그를 찾고 수정하는 작업은 시간이 많이 소요되는 반복적인 일입니다. 최근 대규모 언어 모델(LLM)이 코드 생성에서 뛰어난 성능을 보이면서 이를 활용해 소프트웨어 엔지니어링 작업을 자동화하려는 시도가 활발합니다. 하지만 단순히 강력한 LLM을 사용한다고 해서 복잡한 소프트웨어 엔지니어링 작업을 잘 수행할 수 있을까요?
이 논문은 "인터페이스 설계"가 LLM 에이전트의 성능에 결정적인 영향을 미친다는 점에 주목합니다. 마치 인간 개발자가 VSCode나 PyCharm 같은 IDE를 사용하면 생산성이 향상되는 것처럼 LLM 에이전트도 자신에게 맞는 인터페이스가 필요하다는 것이죠.
2. SWE-agent란? HCI에서 영감을 받은 ACI
SWE-agent의 핵심 아이디어
SWE-agent는 LLM이 소프트웨어 엔지니어링 작업(버그 수정, 기능 추가 등)을 자동으로 수행하도록 돕는 시스템입니다. 핵심은 Agent-Computer Interface(ACI)라는 새로운 개념입니다.
- 아래는 SWE-agent의 구조입니다.
- 프롬프트와 Demo 그리고 문제 설명을 제시하고 LM이 피드백을 기반으로 추론하면서 적절한 액션을 도출합니다.
- ACI는 프롬프트, Demo, 문제 설명 및 LM이 동작할 수 있는 적절한 환경을 구축해줍니다.
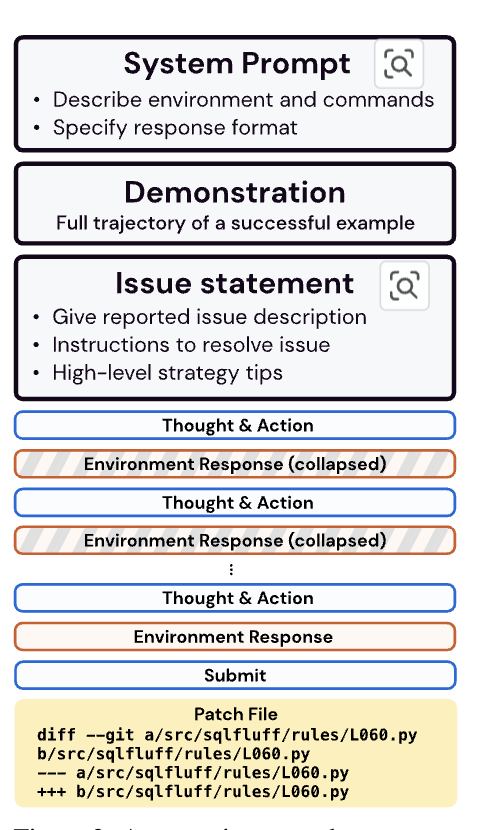
ACI (Agent-Computer Interface)란?
전통적으로 컴퓨터와의 상호작용을 위한 인터페이스 있었습니다.
하지만 LLM 에이전트는 인간도, 전통적인 프로그램도 아닌 새로운 사용자 유형입니다. 따라서 이들을 위한 특별한 인터페이스가 필요합니다.
HCI에서 얻은 인사이트
Human-Computer Interaction(HCI) 분야에서는 오랫동안 "인간에게 맞는 인터페이스를 어떻게 설계할 것인가"를 연구해왔습니다. SWE-agent는 이와 유사하게 "LLM에게 맞는 인터페이스를 어떻게 설계할 것인가"라는 질문에서 출발합니다.

3. SWE-agent의 구성 요소
SWE-agent의 ACI는 크게 4가지 핵심 컴포넌트로 구성됩니다:
🔍 1. Search & Navigation (검색 및 탐색)
대규모 코드베이스에서 관련 파일과 코드를 찾는 것은 버그 수정의 첫 단계입니다.
제공 명령어:
- find_file: 파일명으로 검색
- search_file: 특정 파일 내에서 문자열 검색
- search_dir: 디렉토리 내 모든 파일에서 문자열 검색
특징:
- 검색 결과를 최대 50개로 제한하여 불필요한 정보 감소
- 50개 초과 시 더 구체적인 쿼리를 작성하도록 유도
- 간결하고 구조화된 포맷으로 결과 제시
📄 2. File Viewer (파일 뷰어)
파일 내용을 효과적으로 보여주는 컴포넌트입니다.
주요 기능:
- 한 번에 최대 100줄만 표시 (컨텍스트 관리)
- 각 줄에 줄 번호 표시
- 파일 전체 줄 수와 생략된 줄 수 표시
- scroll_up, scroll_down, goto 명령으로 탐색

✏️ 3. File Editor (파일 에디터)
코드를 수정하는 핵심 컴포넌트입니다.
- edit 명령어란?
edit <시작_줄>:<끝_줄>
<새로운 코드>
end_of_edit
강력한 기능들
- 통합된 편집 프로세스: 한 번의 명령으로 여러 줄 수정 가능
- 즉각적인 피드백: 편집 후 자동으로 업데이트된 파일 내용 표시
- Linting 가드레일:
- 문법 오류가 있으면 편집을 차단
- 에러 발생 전/후 코드를 모두 보여줌
- 구체적인 에러 메시지 제공 (예: "IndentationError")

이를 통해 에이전트가 실수를 즉시 인지하고 수정할 수 있습니다.
🧠 4. Context Management (컨텍스트 관리)
LLM의 제한된 컨텍스트 윈도우를 효율적으로 관리합니다.
전략:
- 최근 5개 관찰(observation)만 전체 내용 유지
- 그 이전 관찰들은 한 줄 요약으로 압축
- 에러 메시지는 첫 번째 것만 유지
- 명령이 출력을 생성하지 않으면 명시적 메시지 표시
효과:
- 불필요한 정보 제거로 더 많은 상호작용 가능
- 오래된 파일 정보로 인한 혼란 방지
- 필수 정보(계획, 액션 히스토리)는 유지
3. ACI 설계 원칙
📋 ACI 설계의 4가지 핵심 원칙
논문은 효과적인 ACI를 설계하기 위한 4가지 원칙을 제시합니다:
1. 단순성 (Simplicity)
"명령어는 단순하고 이해하기 쉬워야 한다"
- Bash 명령어는 수십 개의 옵션이 있어 복잡함
- SWE-agent는 최소한의 옵션만 제공
- 간결한 문서로 에이전트가 쉽게 이해 가능
2. 효율성 (Efficiency)
"중요한 작업은 최소한의 액션으로 완료되어야 한다"
- 여러 단계가 필요한 작업을 하나의 명령으로 통합
- 예: edit 명령은 "파일 열기 → 내용 수정 → 저장 → 확인"을 한 번에 수행
3. 정보성 (Informativeness)
"피드백은 유익하되 간결해야 한다"
- 현재 환경 상태를 명확히 전달
- 불필요한 세부사항은 제거
- 최근 액션의 효과를 구체적으로 알림
4. 에러 방지 (Error Prevention)
"가드레일로 에러 전파를 완화하고 복구를 촉진한다"
- 문법 체크로 잘못된 편집 사전 차단
- 명확한 에러 메시지로 빠른 수정 가능
- 에러 누적을 방지하여 작업 실패 감소
4. ACI 최적화 과정
방법 1: 수동 검사
연구자들이 에이전트의 실제 작동을 관찰하며 문제점을 발견하고 개선안을 제시합니다.
프로세스:
- 개발 데이터셋에서 에이전트 실행
- 실패 사례의 궤적 분석
- 반복되는 실수 패턴 식별
- 인터페이스 개선안 도출
실제 발견 사례:
문제 발견: 에이전트가 sed로 파일을 편집할 때 출력이 없어 불안해함
`$ sed -i "/# trig/i \\'λ':'Symbol(\\"λ\\")'..."
(No Output)
It seems there's a misunderstanding...`
해결책: 편집 전/후 내용을 자동으로 보여주는 edit 명령어 개발
방법 2: 그리드 서치
여러 설정의 조합을 체계적으로 테스트하여 최적값을 찾습니다.
테스트한 하이퍼파라미터
- 파일 뷰어 윈도우 크기
- 후보: 30줄, 100줄, 전체 파일
- 결과: 100줄이 최적
- 이유: 30줄은 너무 적고 전체는 컨텍스트 낭비
- 검색 인터페이스
- Summarized (요약형): 모든 결과 한눈에 표시
- Iterative (순차형): 하나씩 탐색
- 결과: Summarized가 6%p 더 우수
- 편집 인터페이스
- Linting 포함 vs 미포함
- 결과: Linting 포함 시 3%p 향상
- 컨텍스트 관리
- 최근 5개 관찰 vs 전체 히스토리
- 결과: 최근 5개만 유지가 3%p 더 효과적
- Demonstration (시연 예제)
- 포함 vs 미포함
- 결과: 포함 시 1.7%p 향상

4. 실험 결과
📈 주요 성능 지표
SWE-bench 결과
핵심 성과
- 기존 최고 성능(RAG 3.8%) 대비 3.3배 향상
- Shell-only 대비 64% 상대적 향상
- GPT-4와 Claude 3 모두에서 효과 입증 (이식성 확인)

5. 에이전트 행동 패턴 분석
논문은 성공적인 궤적을 분석하여 몇 가지 흥미로운 패턴을 발견했습니다.
1. 재현/지역화가 첫 단계
모든 성공적인 궤적은 다음 중 하나로 시작:
- 재현 (Reproduction): 버그를 재현하는 스크립트 작성
- create → edit → python 시퀀스가 가장 빈번
- 지역화 (Localization): 문제가 있는 코드 위치 파악
- find_file 또는 search_dir로 시작
2. "편집 → 실행" 루프
5턴 이후부터는 대부분의 시간을 다음 패턴으로 소비
편집 시도 → 테스트 실행 → 결과 확인 → 추가 편집 → ...
가장 빈번한 액션은 아래와 같았습니다.
- edit (편집)
- python (실행)
- search_file (추가 탐색)
3. 성공은 빠르게, 실패는 느리게
- SWE-Agent는 가정과 달리 성공한 경우가 실패한 경우보다 평균 비용도 적을 뿐더러 평균 턴 수도 적었습니다. 이는 예산 증가만으로는 성능 향상이 제한적일 것을 시사합니다.
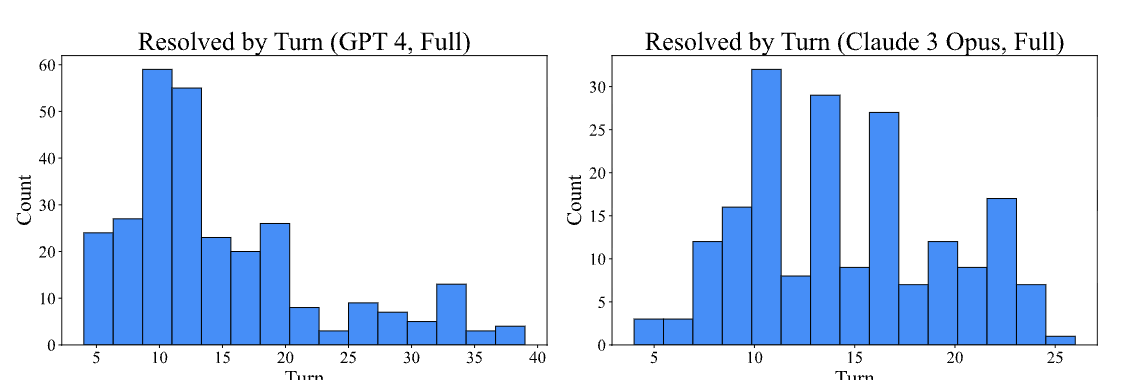
4. 편집은 여전히 어렵다
- 전체 인스턴스의 51.7%에서 1번 이상의 편집 실패 발생
- 첫 시도 성공률: 90.5%
- 한 번 실패 후 복구율: 57.2%로 하락
Linting의 중요성을 한번 더 언급: 에러 연쇄를 차단하여 복구 가능성 향상
'AI' 카테고리의 다른 글
| [AI 논문 리뷰] SWE-bench: 언어 모델은 실제 GitHub 이슈를 해결할 수 있을까? (0) | 2026.01.19 |
|---|---|
| [AI 논문 리뷰] Codex: 자연어로 코드를 생성하는 AI의 등장 (0) | 2026.01.19 |
| LLM: 코드를 이해하고 생성하는 AI 의 등장 (0) | 2026.01.19 |

